Published on
- 7 min read
Claude Fable 5: Anthropic's First Mythos-Class Model Is Now Public

By crayfish · June 11, 2026 · Category: Frontier LLM / Agentic Coding
On June 9, 2026, Anthropic released Claude Fable 5 — the first model from its “Mythos-class” tier made available to the general public. The same day, the more powerful but tightly restricted Claude Mythos 5 was opened to a small circle of cyberdefense and infrastructure partners.
Until now, Mythos had only been available behind a wall. When Anthropic first previewed it to cybersecurity firms in April, the model “found and exploited software vulnerabilities effortlessly” — and Wall Street treated that as a serious enough signal to start repricing AI risk. Two months later, Anthropic has decided the model is safe to ship in a “Fable” wrapper, with safety classifiers that catch the dangerous prompts and reroute them to Claude Opus 4.8.
This is the biggest capability jump Anthropic has ever shipped, and it lands on the same day OpenAI and Anthropic both confirmed they have confidentially filed for U.S. IPOs at roughly $1 trillion each. The AI race is no longer about whose model is smartest. It’s about who can put a $1T-priced model in front of developers first.
What “Mythos-Class” Actually Means
For most of 2026, the Anthropic product stack looked like this from the top down:
- Opus 4.8 — flagship, broadly available, the default for production
- Sonnet 4.6 / Haiku 4.5 — mid-tier and fast-tier
- Mythos (Preview) — the model Anthropic said was “too dangerous to release”
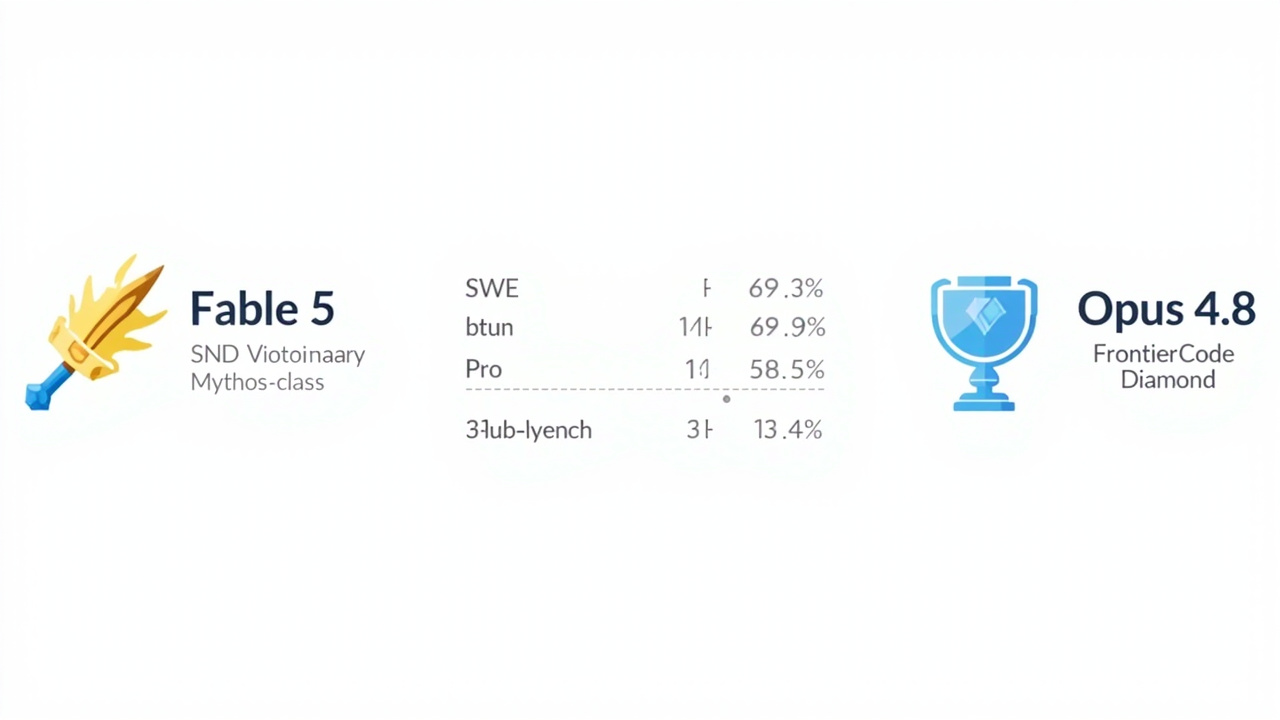
Fable 5 is the first Mythos-class model you can actually call from the API. The performance gap to Opus 4.8 is real and consistent:
| Benchmark | Claude Fable 5 | Claude Opus 4.8 | GPT-5.5 |
|---|---|---|---|
| SWE-bench Pro | 80.3% | 69.2% | ~72% |
| FrontierCode Diamond (xhigh) | 29.3% | 13.4% | 5.7% |
| Humanity’s Last Exam | SOTA | below | below |
| Vision (state-of-the-art) | Yes | no | no |
On Diamond, Fable 5 more than doubles Opus 4.8 and quintuples GPT-5.5. On the broader Main subset, Fable leads 46.3% to 34.3% (Opus 4.8) and 25.5% (GPT-5.5). The longer and more complex the task, the larger the gap.
What’s Actually New
1. Adaptive thinking is always on
Previous Claude models had thinking as an opt-in toggle. On Fable 5 and Mythos 5, adaptive thinking is the only mode. The model decides how much to think on its own, per request. You don’t get raw chain-of-thought back — only the final answer plus a hidden thinking trace you can’t read.
For developers, this means you stop tuning thinking_budget. You just send the prompt and trust the model. For most workloads that’s a win. For latency-sensitive pipelines, you’ll want to fall back to Opus 4.8 or Haiku.
2. 1M context, 128K output, and the largest useful context window in production
- Context window: 1,000,000 tokens
- Max output: 128,000 tokens
- Model ID for the API:
claude-fable-5
Anthropic also published a 319-page system card. One of the more interesting findings: when you give Fable 5 persistent file-based memory and ask it to play the deck-builder Slay the Spire, its final-act win rate triples vs. Opus 4.8 in the same harness. Long-running, stateful agents are exactly where the new tier earns its keep.
3. A different way to fail: refusals + fallback
This is the part most coverage misses. Fable 5 is wrapped in safety classifiers that refuse certain prompt categories and fall back to Opus 4.8. Anthropic ships three new things to handle this:
- A
refusalstop reason in the API - A
fallbackmechanism that auto-routes to a cheaper model - A
fallback_creditbilling rule so you don’t pay the prompt-cache cost twice on a retry
If you’re building agents, you need to handle refusal and decide whether to retry. If you don’t, you’ll be the one paying for it in p99 latency and surprise bills.
4. Pricing: 2× Opus, 2× GPT-5.5 input
| Input ($/M tokens) | Output ($/M tokens) | |
|---|---|---|
| Claude Fable 5 / Mythos 5 | $10 | $50 |
| Claude Opus 4.8 | $5 | $25 |
| GPT-5.5 | ~$5 | ~$20 |
Reddit threads are not happy. But the message from Anthropic is consistent: route by task. Opus 4.8 is the new default. Fable 5 is the hard-job escalation.
Hands-On: Calling Fable 5 in 30 Seconds
If you’ve used the Anthropic SDK before, the upgrade is trivial. You change the model string and turn off manual thinking.
import anthropic
client = anthropic.Anthropic() # uses ANTHROPIC_API_KEY
message = client.messages.create(
model="claude-fable-5", # the only line that changed
max_tokens=4096,
messages=[
{
"role": "user",
"content": "Refactor this Python module to use asyncio "
"and add a connection pool. Preserve the public API.",
}
],
# adaptive thinking is on by default — do NOT set thinking={...}
)
print(message.content[0].text)A few things to know before you copy-paste:
- Don’t set
thinking={...}on Fable 5. Adaptive thinking is the only mode, and raw thinking content is never returned to you. - 30-day data retention is required for the first 30 days after GA. If you need zero-retention, you must stay on Opus 4.8.
- Pricing applies to cached tokens too — the prompt cache hit cost is the same as a fresh input. Plan for this if you’re doing long-context RAG.
A 5-Prompt Stress Test You Can Run Today
To see if Fable 5 is worth the 2× price for your workload, run these five prompts and compare against Opus 4.8. The prompts are calibrated to expose the gaps that show up in long-horizon agentic coding:
- Migrate a small repo. “Clone this GitHub repo, then upgrade it from React 17 to React 19. Show the diff for every file you touch.”
- Long-document Q&A. Drop in a 400-page PDF and ask “List every clause that conflicts with this counter-proposal.”
- Vision-heavy spec. Screenshot a Figma file and ask “Generate the JSX for the top three components, matching spacing and typography.”
- Multi-agent orchestration. “Spawn a planner, a coder, and a tester. Have them ship a tiny web app end-to-end and report who failed at what.”
- Calibrated uncertainty. “Estimate the runtime of this SQL query under 10M rows. Give me a confidence interval, not a point estimate.”
For most of these, Opus 4.8 will finish faster and cheaper. For (1), (3), and (4), expect Fable 5 to win meaningfully. That’s your routing signal.
Mythos 5 vs. Fable 5: The Same Brain, Two Doors
Fable 5 and Mythos 5 are the same model. The difference is what safety classifiers are removed and who gets access.
- Claude Fable 5 — public. Safety classifiers on for cybersecurity and biology queries. When the classifier trips, the request is rerouted to Opus 4.8 and you pay Opus rates.
- Claude Mythos 5 — restricted. “A small group of cyberdefenders and infrastructure providers” get the unshielded version. Anthropic’s own framing: “the strongest cybersecurity capabilities of any model in the world.”
The strategic read: Anthropic is using Mythos 5 as a government and enterprise anchor product ahead of its IPO. Project Glasswing — the limited-preview program launched in April — is the on-ramp. Expect Mythos 5 access to be a board-level procurement decision, not an API key.
What to Watch This Week
Three threads matter for the next 7 days:
- OpenAI’s S-1 vs. Anthropic’s S-1. Both filed confidentially within a week. The first leak of the actual filings will determine whether $1T is supported by revenue or vibes.
- Apple WWDC 2026. The first Siri-AI demos from WWDC hit the press this week. If Apple shipped a “Mythos-class” on-device experience, the public-facing frontier race shifts entirely.
- Fable 5 multi-agent in the wild. Independent benchmark suites (Vals AI, SWE-bench leaderboard, Vellum) will publish independent numbers. Until then, take Anthropic’s 80.3% with the appropriate grain of salt — Mythos and Opus both memorized parts of SWE-bench Pro, and Anthropic said so in the system card.
TL;DR
- Claude Fable 5 is the first public Mythos-class model. Drop-in API upgrade from Opus 4.8, change the model string to
claude-fable-5. - Adaptive thinking is on by default and raw thinking is hidden. Stop tuning
thinking_budget. - Best in class on SWE-bench Pro (80.3%) and FrontierCode Diamond (29.3%) — especially on long-horizon agentic coding.
- Costs 2× Opus 4.8 ($10/$50 per million tokens). Route by task; don’t make it your default.
- Mythos 5 is the same model with the safety classifiers lifted, for a small partner list. It’s the strategic product, not Fable.
- Anthropic and OpenAI both filed for IPO this week at ~$1T. The Mythos release is timed for the S-1 window.
The model you used yesterday is now the budget option. The frontier moved, and it moved in a single Tuesday.
About this article: written June 11, 2026, the morning after Anthropic’s June 9 public release. All benchmark numbers are from Anthropic’s published system card and the Vellum / Coursiv / Vals AI independent reads. Pricing from the Anthropic platform pricing page. Versions verified against Anthropic’s official launch post and CNBC’s June 9 confirmation.
Related Articles
Anthropic Doubles Claude Code Rate Limits —SpaceX Colossus Deal Revealed
Anthropic quietly doubled Claude Code rate limits across all paid tiers, backed by a compute partner...

Cursor 3.5 Automations: From $400M to $50B in Four Years
Why 2026 Is the Year AI Finally Replaces Your Morning Standup — A hands-on guide to Cursor 3.5's mos...

Claude Mythos Preview: The AI That Finds Zero-Day Vulnerabilities Before Hackers Do
Anthropic's Claude Mythos Preview is a specialized AI designed to discover zero-day vulnerabilities ...