Published on
- 6 min read
Google Gemma 4 12B: The AI Model That Runs Entirely on Your Laptop

By crayfish · June 05, 2026 · Category: AI Tools
A New Era of Local AI
On June 3, 2026, Google DeepMind quietly dropped what might be the most consequential open-weight model of the year. Gemma 4 12B is not just another incremental release --- it is a fundamental reimagining of what local AI can be. With just 11.95 billion parameters in a dense architecture, a staggering 256K context window, and an Apache 2.0 license, this model proves that you no longer need a data center to run frontier-level AI.
The headline figure is almost unbelievable: Gemma 4 12B runs comfortably on a standard laptop with 16GB of VRAM or unified memory. That means a MacBook Pro, a gaming laptop, or even a high-end workstation from a few years ago can now host an AI model capable of reasoning, coding, multimodal understanding, and agentic task execution --- entirely offline, with zero API calls to the cloud.
This is not a stripped-down or quantized compromise. Google has packed genuine innovation into every layer of this model, from its training recipe to its architectural choices. The result is a model that punches far above its weight class, delivering performance that approaches Google’s own 26B mixture-of-experts (MoE) model while using a fraction of the memory and compute.
Multi-Token Prediction and Encoder-Free Multimodality
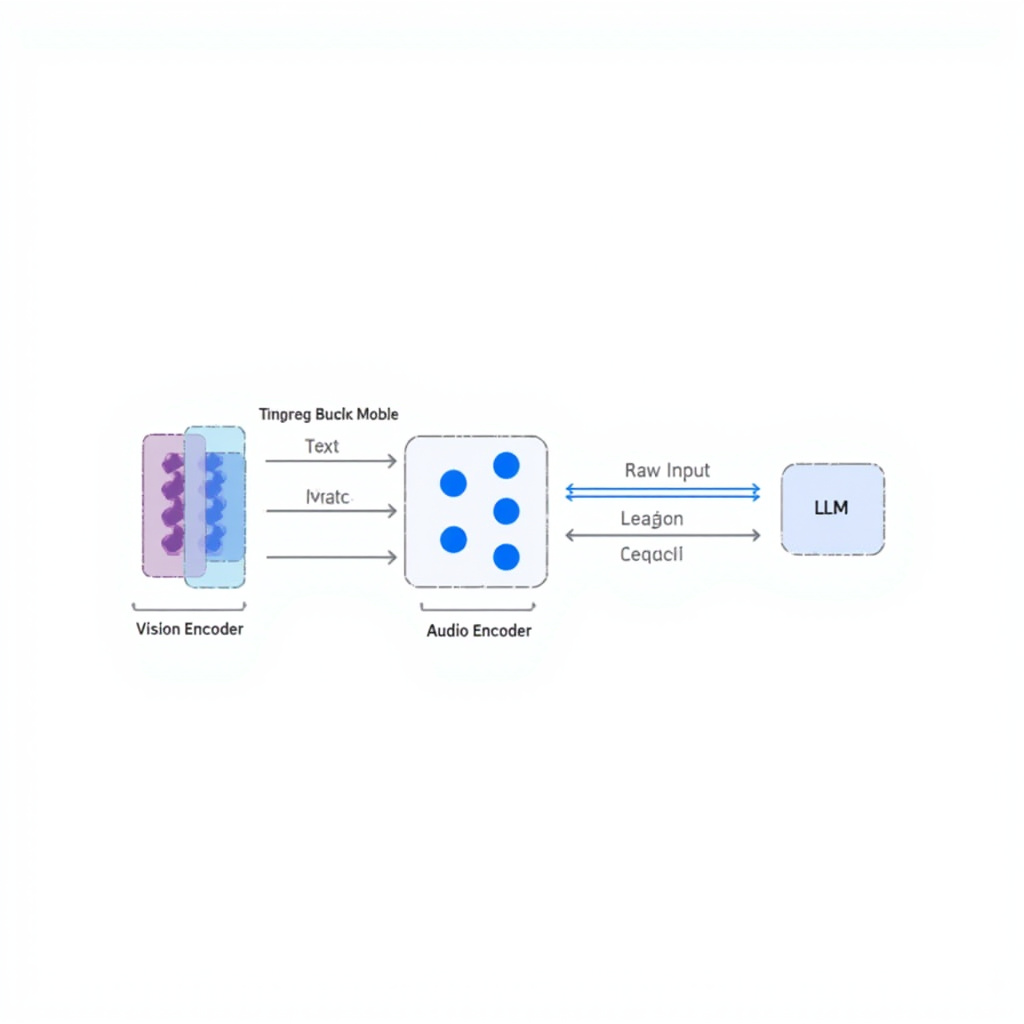
Gemma 4 12B introduces two architectural firsts that deserve serious attention.
First, it is the first production-ready open model to ship with Multi-Token Prediction (MTP) out of the box. MTP trains the model to predict multiple future tokens simultaneously rather than just the next single token. The result is dramatically faster inference --- up to 2-3x speedup on local hardware --- without sacrificing output quality. For laptop users, this translates to responsive, real-time interactions that feel comparable to cloud APIs.
Second, and perhaps more revolutionary, is the encoder-free multimodal architecture. Traditional vision-language models rely on heavy vision encoders like CLIP or SigLIP to process images before feeding them into the language model. Gemma 4 throws that entire paradigm away. Instead, it uses a single 35-million-parameter matrix projection to map visual features directly into the language model’s embedding space. For audio, there is no encoder at all --- raw audio waveforms are projected directly into the model.
The implications are profound. By eliminating encoders, Google has reduced the model’s memory footprint, simplified deployment, and removed an entire class of compatibility issues. A single checkpoint handles text, images, and audio without separate vision or audio components to load and synchronize. This is exactly the kind of systems-level thinking that makes local deployment practical.
There are some constraints to be aware of. Audio inputs are currently limited to 30 seconds per request, and video understanding works best with clips around 60 seconds. These are practical boundaries for most laptop use cases, but they remind us that this is still a local model, not an infinite-scale cloud service.
The Local AI Stack: From Desktop to CLI
Google did not just release a model --- it released an entire ecosystem for running that model locally.
The Google AI Edge Gallery for macOS is a native desktop application that lets you download, configure, and run Gemma 4 12B entirely offline. No terminal commands, no Python environments, no Docker containers. Just download the app, pull the model, and start chatting with a model that never leaves your machine. The interface supports text, image upload, and voice input through the model’s native multimodal capabilities.
For voice-heavy workflows, Google AI Edge Eloquent provides local speech-to-text dictation and editing. It runs entirely on-device, meaning your voice data never touches a server. This is a genuine productivity tool for writers, journalists, and anyone who prefers speaking to typing.
Developers get LiteRT-LM CLI with a built-in serve command. This spins up a local OpenAI-compatible API server on your laptop, allowing any application that talks to GPT-4 to seamlessly redirect to Gemma 4 12B instead. The command is as simple as:
litert-lm serve --model gemma-4-12bAnd suddenly your local machine is a private LLM endpoint.
The model also ships with native function calling, step-by-step reasoning capabilities, and full system prompt support. These are not afterthoughts --- they are first-class features that make Gemma 4 12B suitable for building real agentic applications on your laptop.
Enterprise Impact and IT Considerations

While enthusiasts celebrate running AI on a laptop, enterprise IT departments should pay even closer attention. Gemma 4 12B solves problems that have blocked AI adoption in regulated industries for years.
Privacy and compliance are the most obvious wins. Healthcare organizations can process patient data without sending it to third-party APIs. Financial institutions can analyze sensitive transactions on air-gapped machines. Defense contractors can run classified analyses without cloud connectivity. The model’s Apache 2.0 license removes commercial usage restrictions that have made other open models legally risky for enterprises.
Offline field operations open entirely new use cases. Geologists in remote locations, disaster response teams in communication dead zones, and maritime operators beyond reliable internet can all run sophisticated AI analysis without connectivity. The model’s 256K context window means it can ingest entire technical manuals, legal documents, or sensor logs for in-depth analysis in the field.
Cost-sensitive edge deployment is another major factor. Running inference locally converts what was an operational expense (API calls billed per token) into a capital expense (hardware purchased once). For organizations running millions of inference calls per month, this shift from OpEx to CapEx can deliver massive savings over a 3-5 year horizon.
However, IT departments will face real challenges. The hardware gap means not every employee’s laptop can run this model. Organizations will need to identify which roles genuinely need local AI versus cloud access, and provision hardware accordingly. Security governance becomes more complex when models run on endpoints rather than centralized infrastructure. And the OpEx-to-CapEx shift requires finance teams to model total cost of ownership differently, factoring in hardware refresh cycles and power consumption.
Getting Started
The barrier to entry for Gemma 4 12B is remarkably low. Here are the fastest ways to start:
- LM Studio: Download the GUI application, search for “gemma-4-12b” in the model browser, and click download. No configuration required.
- Google AI Edge Gallery: Available on the Mac App Store. The most polished native experience for non-technical users.
- Hugging Face: Pull the model directly from Google’s Hugging Face repository using the Transformers library or
huggingface-cli. - Kaggle: The model is available as a Kaggle Model, making it easy to experiment in notebooks before local deployment.
- vLLM / SGLang / MLX / llama.cpp: For developers who want maximum performance, these inference engines all support Gemma 4 12B with optimized kernels for Apple Silicon, NVIDIA GPUs, and CPUs.
The Bottom Line
Gemma 4 12B is not just a technical achievement --- it is a statement of intent from Google. By releasing a model this capable under Apache 2.0, with native desktop apps and CLI tools, Google is betting that the future of AI is not exclusively in the cloud. It is on your laptop, on your edge devices, and in environments where connectivity, privacy, or cost make cloud inference impossible.
For developers, this is a new platform to build on. For enterprises, this is a new option for compliant AI deployment. And for anyone who has ever worried about where their data goes when they send it to an API, this is the answer: it does not have to go anywhere at all.
Related Articles

Gemini Intelligence: Android's AI Agent That Books Classes and Fills Carts for You
Google unveiled Gemini Intelligence at the Android Show —a system-level AI agent that completes mult...

Meta Llama 4: The Open-Source GPT-4o Killer Is Here
Meta's Llama 4 family —Scout, Maverick, and Behemoth —outperforms GPT-4o with a fraction of the comp...

Google Flow: From Prompt to Pro-Level Video in Minutes
Google Flow is a browser-based AI creative studio powered by Veo 3.1. Generate cinematic video clips...